Hypothesis Test for One Mean
One Sample Z Test is used to test whether one sample mean is significantly different from a hypothesized population mean when the population standard deviation is known or when a large-sample z approximation is used. This guide explains the one sample z test formula, null hypothesis, alternative hypothesis, assumptions, p-value, confidence interval, SPSS image output, Python charts, R validation charts and Excel workflow using G3 final grade data.
Google AdSense top placement reserved here
Quick Answer: One Sample Z Test Result
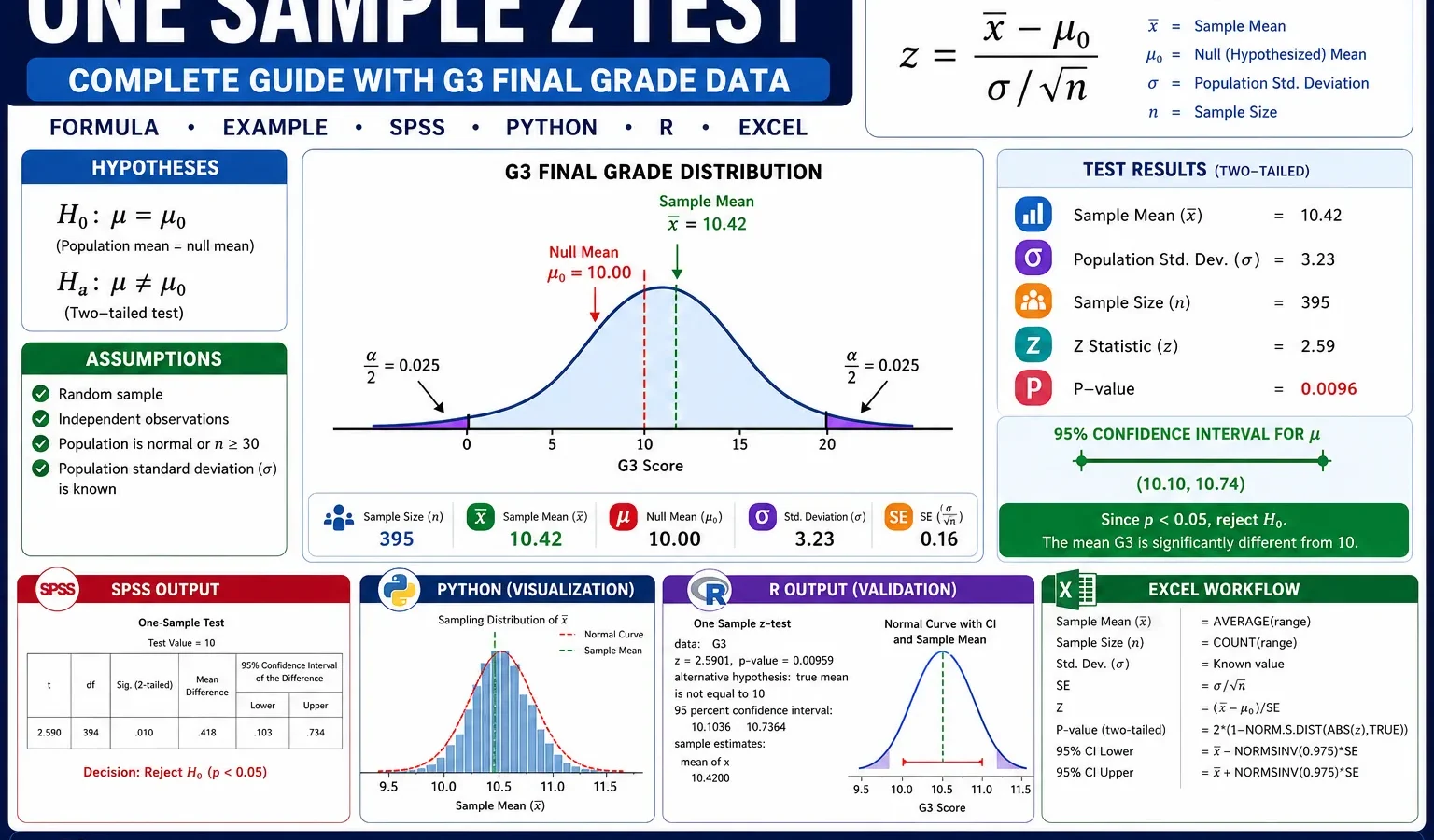
The One Sample Z Test was performed to test whether the mean G3 final grade was significantly different from the hypothesized mean of μ0 = 10. The sample contained n = 649 valid students. The sample mean was M = 11.9060, and the standard deviation used for the z test was σ = 3.2307.
The standard error was SE = 0.1268. The z statistic was z = 15.0299, and the two-tailed p-value was extremely small, approximately 4.68 × 10-51. In a final report, this should be written as p < .001. The 95% confidence interval for the mean G3 score was approximately [11.6575, 12.1546].
Final conclusion: Since p < .001, reject the null hypothesis. The sample provides very strong evidence that the population mean G3 final grade is significantly different from 10. Because the sample mean is 11.9060, the practical conclusion is that the mean G3 final grade is significantly higher than the benchmark value of 10.
Important note: A textbook one sample z test assumes that the population standard deviation is known. If the population standard deviation is unknown and only the sample standard deviation is available, a one-sample t test is usually the formal textbook choice. In this worked example, the z-test workflow uses σ = 3.2307 with a large sample size of 649.
Table of Contents
- What Is a One Sample Z Test?
- When Should You Use a One Sample Z Test?
- Null and Alternative Hypothesis
- One Sample Z Test Formula
- Conditions and Assumptions
- Dataset and Variable Used
- Verified Results Summary
- SPSS Image Output and Interpretation
- Python Charts and Interpretation
- R Validation Charts and Interpretation
- Overall Image Interpretation
- How to Run the Test in SPSS, Python, R and Excel
- How to Report the One Sample Z Test
- Common Mistakes
- FAQs
What Is a One Sample Z Test?
A One Sample Z Test is a hypothesis test used to compare one sample mean with one hypothesized population mean. It is a test for one continuous variable. The test answers a question such as: Is the average G3 final grade different from 10?
The test compares the observed sample mean, written as M or x̄, with the null hypothesis mean, written as μ0. The difference between the sample mean and the null mean is divided by the standard error. This produces the z statistic. The z statistic is then interpreted using the standard normal distribution.
In this post, the continuous outcome is G3 final grade. The null hypothesis benchmark is μ0 = 10. The observed sample mean is 11.9060. The test asks whether the population mean G3 final grade is different from 10.
For background concepts, see Null and Alternative Hypothesis, P Value, Z Score, Standard Error and Standard Normal Distribution.
When Should You Use a One Sample Z Test?
Use a one sample z test when you have one sample, one continuous outcome and one hypothesized mean. The test is most appropriate when the population standard deviation is known. With a large sample, the z workflow is also often used as an approximation.
| Situation | Use One Sample Z Test? | Reason |
|---|---|---|
| Testing whether mean G3 differs from 10 | Yes | G3 is continuous, and the comparison is against one hypothesized mean. |
| Testing whether average exam score differs from a passing benchmark | Yes | The outcome is a numeric score, and there is one reference mean. |
| Testing whether average delivery time differs from 3 days | Yes | The outcome is continuous, and 3 days is the null mean. |
| Testing whether pass proportion differs from 50% | No | That is a proportion question. Use a One Proportion Z Test. |
| Comparing mean G3 between two schools | No | That is a two-group mean comparison, not a one-sample test. |
Null and Alternative Hypothesis for One Sample Z Test
The hypotheses describe the claim being tested. In this example, the null hypothesis says that the population mean G3 final grade is equal to 10. The alternative hypothesis says that the population mean G3 final grade is not equal to 10.
| Hypothesis | Symbolic form | Meaning in this example |
|---|---|---|
| Null hypothesis | H0: μ = 10 | The population mean G3 final grade is 10. |
| Alternative hypothesis | H1: μ ≠ 10 | The population mean G3 final grade is not 10. |
| Decision rule | Reject H0 if p-value < α | Using α = .05, reject H0 because p < .001. |
This is a two-tailed test because the alternative hypothesis uses “not equal to.” If the research question were specifically whether the mean G3 grade is greater than 10, the alternative hypothesis would be H1: μ > 10. If the research question were whether the mean G3 grade is lower than 10, the alternative hypothesis would be H1: μ < 10. For directional testing context, see One Tailed T Test.
One Sample Z Test Formula and Calculation
The One Sample Z Test formula is:
z = (x̄ - μ0) / (σ / √n)
where:
x̄ = sample mean
μ0 = hypothesized population mean
σ = known population standard deviation or z-test standard deviation
n = sample sizeFor this worked example, the values are:
| Component | Value | Explanation |
|---|---|---|
| Sample size | n = 649 | Total valid G3 final grade records. |
| Sample mean | x̄ = 11.9060 | Observed mean G3 final grade. |
| Null mean | μ0 = 10.0000 | Hypothesized benchmark mean. |
| Standard deviation used | σ = 3.2307 | Standard deviation used for the z-test standard error. |
| Standard error | SE = 0.1268 | σ / √n = 3.2307 / √649. |
| Z statistic | z = 15.0299 | The sample mean is 15.03 standard errors above the null mean. |
| Two-tailed p-value | p < .001 | The result is statistically significant. |
x̄ = 11.9060
μ0 = 10.0000
σ = 3.2307
n = 649
SE = σ / √n
SE = 3.2307 / √649
SE = 0.1268
z = (11.9060 - 10.0000) / 0.1268
z = 15.0299The 95% confidence interval for the mean is calculated as:
95% CI = x̄ ± 1.96 × SE
95% CI = 11.9060 ± 1.96 × 0.1268
95% CI = [11.6575, 12.1546]The confidence interval is entirely above 10, which supports the same decision as the p-value. For more explanation, see Confidence Interval, Margin of Error and Standard Deviation.
Conditions and Assumptions for One Sample Z Test
The One Sample Z Test has several important assumptions. These assumptions explain when the z statistic and p-value can be trusted.
| Condition | How to check it | This example |
|---|---|---|
| Continuous outcome | The dependent variable should be numeric. | G3 final grade is numeric. |
| One sample | The test analyzes one sample mean. | The test uses one overall sample of 649 students. |
| Independence | Each observation should represent a separate case. | Each row is treated as one independent student record. |
| Known standard deviation or large-sample approximation | The z test assumes σ is known, or a large-sample z approximation is used. | The workflow uses σ = 3.2307 with n = 649. |
| Approximately normal sampling distribution | The sample mean should have an approximately normal sampling distribution. | With n = 649, the Central Limit Theorem supports the z approximation. |
For more background on normal approximation and sampling distributions, see Central Limit Theorem, Normal Distribution and Parametric vs Nonparametric Tests.
Dataset and Variable Used
This worked example uses student performance data. The outcome variable is G3 final grade, which is a numeric final grade score. The one sample z test compares the observed mean G3 score with the null hypothesis mean of 10.
| Item | Value | Explanation |
|---|---|---|
| Outcome variable | G3 | Final grade score. |
| Scale | 0 to 20 | G3 is measured as a numeric grade. |
| Sample size | 649 | Total valid observations. |
| Sample mean | 11.9060 | Observed mean final grade. |
| Standard deviation | 3.2307 | Standard deviation used in the z-test calculation. |
| Null mean | 10.0000 | Benchmark mean used in the hypothesis test. |
External dataset source: UCI Machine Learning Repository: Student Performance dataset.
Google AdSense middle placement reserved here
Verified SPSS, Python and R Results Summary
The SPSS image output, Python charts and R validation charts all support the same conclusion. The sample mean G3 final grade is clearly above the null hypothesis mean of 10. The confidence interval is entirely above 10, and the z statistic is far into the rejection region of the standard normal curve.
| Statistic | Value | Interpretation |
|---|---|---|
| Sample size | 649 | All valid G3 records. |
| Sample mean | 11.9060 | The observed mean final grade is above 10. |
| Null mean | 10.0000 | The hypothesized benchmark mean. |
| Standard deviation used | 3.2307 | Used to calculate the z-test standard error. |
| Standard error | 0.1268 | The estimated standard deviation of the sample mean. |
| Z statistic | 15.0299 | The sample mean is very far above the null mean. |
| Two-tailed p-value | p < .001 | Reject H0. |
| 95% confidence interval | [11.6575, 12.1546] | The estimated population mean is above 10. |
SPSS Image Output and Interpretation
The SPSS image output explains the result visually. Instead of relying only on a table, the images show the G3 distribution, the sample mean compared with the null mean, the confidence interval, the z statistic on the standard normal curve and descriptive mean G3 differences by school, sex and study time.
1. SPSS Image: G3 Distribution with Null Mean and Sample Mean

This SPSS image shows the distribution of G3 final grades. It also marks the null hypothesis mean, μ0 = 10, and the observed sample mean, x̄ = 11.9060. The purpose of this chart is to show the test comparison in the original grade scale before the result is standardized into a z statistic.
The sample mean is visibly to the right of the null mean. This means the average final grade in the sample is higher than the benchmark value of 10. The difference between the sample mean and null mean is 11.9060 − 10 = 1.9060 grade points. This is the raw mean difference that becomes the numerator of the z statistic.
The chart also helps readers understand why the result is not only statistically significant but also easy to explain. The test is not comparing two hidden numbers. It is comparing the observed center of the G3 distribution with a fixed benchmark line at 10.
2. SPSS Image: Sample Mean versus Null Mean

This SPSS image focuses directly on the comparison between the sample mean and the null mean. The sample mean is 11.9060, while the null mean is 10.0000. The observed sample mean is therefore 1.9060 points higher than the null value.
This is the central comparison in the One Sample Z Test. The z test asks whether this mean difference is large relative to the standard error of the mean. Because the sample size is 649, the standard error is small, only 0.1268. A difference of 1.9060 divided by 0.1268 produces a very large z statistic.
The SPSS image therefore supports the hypothesis-test decision visually. The observed mean is not close to the null mean. It is clearly above it, and the formal z test confirms that the difference is statistically significant.
3. SPSS Image: Confidence Interval for the Mean

This SPSS image shows the 95% confidence interval for the population mean G3 final grade. The interval is approximately [11.6575, 12.1546]. This means that the estimated population mean G3 grade is likely between about 11.66 and 12.15.
The confidence interval is important because it gives more information than the p-value alone. The p-value tells us whether the null hypothesis should be rejected. The confidence interval shows the likely range of the true mean. In this case, the entire interval is above 10.
Because the interval does not include the null mean of 10, the confidence interval supports the same decision as the z test. The mean G3 final grade is statistically significantly higher than 10.
4. SPSS Image: Z Statistic on the Standard Normal Curve

This SPSS image places the z statistic on the standard normal curve. The observed z statistic is z = 15.0299. A z statistic of this size is extremely far to the right of zero, which means the sample mean is far above the null mean after standardization.
For a two-tailed test at α = .05, the usual critical values are approximately -1.96 and +1.96. The observed value of 15.0299 is far greater than +1.96. This puts the result deep inside the rejection region.
The standard normal curve image explains why the p-value is extremely small. Under the null hypothesis, a z value this extreme would be extraordinarily unlikely. Therefore, the correct decision is to reject H0: μ = 10.
5. SPSS Image: Mean G3 by School

This SPSS image provides subgroup context by school. It shows the mean G3 final grade separately for the school categories. This is not the formal One Sample Z Test itself, because the main test uses the overall mean of all 649 students. However, it helps readers understand where the overall mean comes from.
The school chart shows that mean G3 differs across school categories. The descriptive school means are useful for interpretation, but they should not be treated as a formal test of school differences. If the research question were whether schools differ significantly in mean G3, a separate two-group mean comparison would be needed.
For the One Sample Z Test, the key result remains the overall mean: x̄ = 11.9060. The school chart is supportive descriptive context, while the formal hypothesis test compares the overall sample mean with μ0 = 10.
6. SPSS Image: Mean G3 by Sex

This SPSS image shows descriptive mean G3 final grade by sex. The subgroup means provide useful context for the overall sample mean. The formal One Sample Z Test does not test sex differences; it tests whether the overall mean G3 score differs from the null mean of 10.
The sex chart helps readers understand whether the overall mean is being driven by one subgroup or whether the mean pattern is visible across categories. It is descriptive and should be interpreted alongside the main test result, not as a replacement for it.
If the goal is to test whether female and male students differ significantly in mean G3, a separate two-sample mean test would be required. In this article, the sex chart is included only to explain the data context behind the overall one-sample result.
7. SPSS Image: Mean G3 by Study Time

This SPSS image shows mean G3 final grade by study time category. Study time is coded in ordered categories, so the chart is useful for understanding how average final grade changes across study-time groups. It provides educational context because study time is naturally related to exam performance.
The main One Sample Z Test does not test study-time differences. It uses the overall sample mean of 11.9060 and compares it with μ0 = 10. The study-time chart is therefore descriptive, not inferential.
If the goal is to formally compare mean G3 across multiple study-time groups, an ANOVA or regression model would be more appropriate. For this post, the chart helps explain the distribution of mean G3 across study habits while the main hypothesis decision remains based on the overall mean.
Python Charts and Interpretation
The Python charts validate the same One Sample Z Test result using a programmatic workflow. Python confirms the sample mean, null mean, confidence interval, z statistic and descriptive subgroup charts.
1. Python Chart: G3 Distribution with Null Mean and Sample Mean

The Python distribution chart confirms the same visual comparison shown in the SPSS section. The G3 distribution is shown with a reference line for the null mean of 10 and a reference line for the sample mean of 11.9060.
This chart shows the raw data context for the test. The sample mean is to the right of the null mean, indicating that the average final grade is above the benchmark. The raw difference is 1.9060 grade points.
The Python chart is useful because it confirms that the test result is not just a table value. The observed center of the G3 distribution is visually higher than the null benchmark.
2. Python Chart: Sample Mean versus Null Mean

The Python sample-mean chart focuses on the direct comparison between x̄ = 11.9060 and μ0 = 10. The visual gap between the two values is the main effect being tested.
Because the sample size is large, the standard error is small. This means that a difference of 1.9060 grade points becomes a very large standardized difference. The resulting z statistic is 15.0299.
The Python chart therefore supports the same conclusion as the SPSS chart: the sample mean is clearly above the null mean, and the formal test confirms that the difference is statistically significant.
3. Python Chart: Confidence Interval for the Mean

The Python confidence interval chart shows the estimated range for the population mean G3 final grade. The 95% confidence interval is approximately [11.6575, 12.1546].
The entire confidence interval is above the null value of 10. This is important because it gives an interval-based confirmation of the hypothesis decision. If the interval had included 10, the evidence against the null would be weaker. Here, the interval is far above 10.
The chart also helps communicate practical meaning. The estimated population mean is not just slightly above 10; it is likely around the high 11s to low 12s.
4. Python Chart: Z Statistic on the Standard Normal Curve

The Python standard normal curve chart shows where the test statistic falls under the standard normal distribution. The observed test statistic is z = 15.0299, which is far to the right of the center of the curve.
The usual two-tailed α = .05 rejection boundaries are approximately -1.96 and +1.96. The observed z statistic is much larger than +1.96. This means the observed sample mean is far outside the range expected under the null hypothesis.
The p-value is extremely small because the tail probability beyond such an extreme z statistic is tiny. Therefore, the Python chart validates the decision to reject the null hypothesis.
5. Python Chart: Mean G3 by School

The Python school chart provides descriptive context for the overall mean. It separates mean G3 by school category. This helps readers see whether the overall mean is similar across school groups or whether the groups show different average performance.
This chart does not change the One Sample Z Test result. The formal test uses the overall mean 11.9060 and compares it with the null mean 10. The school chart is a descriptive follow-up image.
If the research question were about school differences, a two-group mean comparison would be needed. Here, the school chart simply helps explain the structure of the G3 data.
6. Python Chart: Mean G3 by Sex

The Python sex chart shows mean G3 by sex category. This chart is descriptive and helps readers understand how the overall mean is distributed across sex groups.
The main One Sample Z Test is not a test of sex differences. It is a test of whether the overall mean G3 score differs from 10. The sex chart should therefore be interpreted as supporting context.
Because the overall sample mean is significantly above 10, subgroup charts like this help explain the data pattern but do not replace the formal one-sample decision.
7. Python Chart: Mean G3 by Study Time

The Python study-time chart shows mean G3 across ordered study-time categories. This chart helps interpret whether students with different study-time categories show different average final grades.
The chart is descriptive rather than inferential. The One Sample Z Test still uses the overall sample mean of 11.9060. It does not test whether study-time categories differ significantly from each other.
If study-time differences are the main research question, a separate ANOVA or regression model should be used. For this article, the Python study-time chart is included to provide a fuller understanding of the G3 data.
R Validation Charts and Interpretation
The R charts provide another validation of the same One Sample Z Test result. R confirms the distribution, sample mean, null mean, confidence interval, standard normal curve and subgroup summaries.
1. R Chart: G3 Distribution with Null Mean and Sample Mean

The R distribution chart confirms the same result shown by SPSS and Python. The null mean is 10, while the sample mean is 11.9060. The sample mean is to the right of the null mean.
This chart validates the raw comparison behind the test. The observed mean G3 score is higher than the benchmark value. The difference is 1.9060 grade points.
Because R produces the same visual result, it supports the consistency of the analysis across software workflows.
2. R Chart: Sample Mean versus Null Mean

The R sample-mean chart confirms that the observed sample mean is above the null mean. The comparison is 11.9060 versus 10.0000.
This is the main difference tested by the One Sample Z Test. The chart shows the raw difference, while the z statistic standardizes it by the standard error.
Since the difference is large relative to the standard error, the final z statistic is very large. The R chart therefore supports the same hypothesis decision as the SPSS and Python charts.
3. R Chart: Confidence Interval for the Mean

The R confidence interval chart confirms the same interval estimate: approximately [11.6575, 12.1546]. This interval is centered around the sample mean of 11.9060.
The key interpretation is that the entire interval is above 10. This means the estimated population mean G3 score remains above the null benchmark even after accounting for sampling uncertainty.
The confidence interval therefore supports the same conclusion as the p-value: reject the null hypothesis and conclude that the mean G3 final grade is significantly different from 10.
4. R Chart: Z Statistic on the Standard Normal Curve

The R standard normal curve chart confirms the formal test decision. The observed z statistic is 15.0299, far beyond the usual rejection cutoff for a two-tailed test at α = .05.
A value this extreme means the observed mean would be extraordinarily unlikely if the true population mean were exactly 10. The p-value is therefore extremely small.
The R chart validates the final decision: reject H0: μ = 10. The sample mean G3 score is significantly higher than the null benchmark.
5. R Chart: Mean G3 by School

The R school chart repeats the descriptive school summary. It helps explain how average G3 final grade differs across school categories.
This chart is useful for context, but it is not the main one-sample hypothesis test. The formal test uses the overall mean of 11.9060 and compares it with 10.
If school differences are important, a separate two-group test should be performed. In this article, the school chart helps readers understand the data behind the overall z test.
6. R Chart: Mean G3 by Sex

The R sex chart confirms the descriptive mean G3 pattern by sex category. It provides subgroup context for the overall mean.
The chart should not be interpreted as a formal hypothesis test of sex differences. It is included to help readers see how the overall G3 mean is distributed across categories.
The formal One Sample Z Test remains focused on the overall sample mean compared with the null mean of 10.
7. R Chart: Mean G3 by Study Time

The R study-time chart shows mean G3 across study-time categories. It provides descriptive context about how average final grade changes across levels of study time.
This chart does not change the one-sample z test result. The main test is based on the overall mean of 11.9060, not separate category means.
For a formal test of study-time group differences, use a separate group-comparison method. In this post, the R study-time chart is a validation chart that supports the broader interpretation of the G3 data.
Overall Interpretation of All SPSS, Python and R Images
All image sets tell the same statistical story. The distribution images show that the sample mean is above the null mean. The mean-comparison images show that 11.9060 is higher than 10.0000. The confidence interval images show that the 95% confidence interval, [11.6575, 12.1546], is entirely above the null value. The standard normal curve images show that z = 15.0299 is far into the rejection region.
| Image type | Main message | How it supports the test |
|---|---|---|
| G3 distribution images | Sample mean is above the null mean | Shows the raw data context for the test. |
| Sample mean vs null mean images | 11.9060 is above 10.0000 | Shows the tested mean difference. |
| Confidence interval images | 95% CI is [11.6575, 12.1546] | Shows that the estimated mean is above 10. |
| Z statistic curve images | z = 15.0299 | Shows that the result is far into the rejection region. |
| School subgroup images | Mean G3 is summarized by school | Provides descriptive context for the overall mean. |
| Sex subgroup images | Mean G3 is summarized by sex | Provides descriptive context for the overall mean. |
| Study-time subgroup images | Mean G3 is summarized by study-time category | Provides descriptive context for the overall mean. |
The final decision is consistent across SPSS, Python and R: reject the null hypothesis. The mean G3 final grade is statistically significantly different from 10, and the observed direction shows that the mean is higher than 10.
How to Run One Sample Z Test in SPSS, Python, R and Excel
SPSS Method
SPSS does not always provide a direct one-click one sample z test menu option, so the clean method is to compute the z statistic from the mean, standard deviation, sample size and null mean.
* One Sample Z Test in SPSS.
* Test whether mean G3 differs from 10.
AGGREGATE
/OUTFILE=* MODE=ADDVARIABLES
/BREAK=
/N_G3=N(G3)
/Mean_G3=MEAN(G3)
/SD_G3=SD(G3).
COMPUTE mu0 = 10.
COMPUTE se_mean = SD_G3 / SQRT(N_G3).
COMPUTE z_value = (Mean_G3 - mu0) / se_mean.
COMPUTE p_value_two_tailed = 2 * (1 - CDF.NORMAL(ABS(z_value), 0, 1)).
COMPUTE ci_95_low = Mean_G3 - 1.96 * se_mean.
COMPUTE ci_95_high = Mean_G3 + 1.96 * se_mean.
EXECUTE.Python Method
Python can calculate the one sample z test using pandas and the standard normal distribution.
import math
import pandas as pd
df = pd.read_csv("student_data.csv")
mu0 = 10
alpha = 0.05
g3 = df["G3"].dropna()
n = len(g3)
mean_g3 = g3.mean()
sigma = g3.std(ddof=1)
se = sigma / math.sqrt(n)
z_value = (mean_g3 - mu0) / se
p_value_two_tailed = math.erfc(abs(z_value) / math.sqrt(2))
ci_low = mean_g3 - 1.96 * se
ci_high = mean_g3 + 1.96 * se
decision = "Reject H0" if p_value_two_tailed < alpha else "Fail to reject H0"
print("n:", n)
print("Mean G3:", mean_g3)
print("SD used:", sigma)
print("SE:", se)
print("z:", z_value)
print("p-value:", p_value_two_tailed)
print("95% CI:", ci_low, ci_high)
print("Decision:", decision)R Method
R can reproduce the same result by calculating the mean, standard deviation, standard error, z statistic and p-value.
df <- read.csv("student_data.csv")
mu0 <- 10
alpha <- 0.05
g3 <- na.omit(df$G3)
n <- length(g3)
mean_g3 <- mean(g3)
sigma <- sd(g3)
se <- sigma / sqrt(n)
z_value <- (mean_g3 - mu0) / se
p_value_two_tailed <- 2 * (1 - pnorm(abs(z_value)))
ci_low <- mean_g3 - 1.96 * se
ci_high <- mean_g3 + 1.96 * se
decision <- ifelse(p_value_two_tailed < alpha, "Reject H0", "Fail to reject H0")
data.frame(
n = n,
mean_g3 = mean_g3,
sigma = sigma,
se = se,
z_value = z_value,
p_value_two_tailed = p_value_two_tailed,
ci_low = ci_low,
ci_high = ci_high,
decision = decision
)Excel Method
Excel can calculate the One Sample Z Test using standard formulas. Suppose G3 grades are in cells A2:A650.
| Step | Excel formula | Purpose |
|---|---|---|
| Sample size | =COUNT(A2:A650) | Calculates n. |
| Sample mean | =AVERAGE(A2:A650) | Calculates x̄. |
| Standard deviation | =STDEV.S(A2:A650) | Calculates the standard deviation used for the z workflow. |
| Standard error | =sd_cell/SQRT(n_cell) | Calculates SE. |
| Z statistic | =(mean_cell-mu0_cell)/se_cell | Calculates the test statistic. |
| Two-tailed p-value | =2*(1-NORM.S.DIST(ABS(z_cell),TRUE)) | Calculates the p-value. |
| 95% CI lower | =mean_cell-1.96*se_cell | Lower confidence bound. |
| 95% CI upper | =mean_cell+1.96*se_cell | Upper confidence bound. |
How to Report the One Sample Z Test
A complete report should include the null mean, sample size, sample mean, standard deviation used, standard error, z statistic, p-value, confidence interval and decision.
APA-style report: A one sample z test was conducted to determine whether the mean G3 final grade differed from 10. The sample mean was 11.9060 based on 649 students, with σ = 3.2307. The result was statistically significant, z = 15.0299, p < .001, 95% CI [11.6575, 12.1546]. Therefore, the null hypothesis was rejected. The data provide strong evidence that the population mean G3 final grade is higher than 10.
In plain language, the average G3 final grade in the sample was about 11.91, which is significantly higher than the benchmark value of 10. The estimated population mean is likely between about 11.66 and 12.15.
Common Mistakes in One Sample Z Test Interpretation
1. Reporting p = .000
Software may display very small p-values as .000. This is only rounding. Report the result as p < .001.
2. Confusing the sample mean and null mean
The sample mean is the observed value from the data. In this example, x̄ = 11.9060. The null mean is the benchmark value, μ0 = 10.
3. Forgetting the standard error
The z statistic is not based only on the raw difference between means. It divides the mean difference by the standard error.
4. Using a z test when a t test is required
A formal one sample z test assumes the population standard deviation is known. If the population standard deviation is unknown, a one-sample t test is usually preferred.
5. Treating subgroup charts as the main hypothesis test
The school, sex and study-time images are descriptive context. They do not replace the formal one sample z test of the overall mean.
6. Ignoring practical meaning
A statistically significant result should also be interpreted in the original units. Here, the sample mean is about 1.9060 grade points higher than the null mean of 10.
FAQs About One Sample Z Test
What is a One Sample Z Test?
A One Sample Z Test is a hypothesis test used to compare one sample mean with a hypothesized population mean.
What is the formula for a One Sample Z Test?
The formula is z = (x̄ − μ0) / (σ / √n).
What was the result in this example?
The result was n = 649, x̄ = 11.9060, μ0 = 10, σ = 3.2307, SE = 0.1268, z = 15.0299 and p < .001. The null hypothesis was rejected.
What does the confidence interval mean?
The 95% confidence interval of approximately [11.6575, 12.1546] means the population mean G3 final grade is estimated to be between about 11.66 and 12.15.
Why is the p-value reported as p < .001?
The p-value is extremely small. Software may display it as .000, but the correct report is p < .001.
Can I run a One Sample Z Test in SPSS?
Yes. You can calculate the sample mean, standard deviation, standard error, z statistic, p-value and confidence interval using SPSS syntax.
Can I run a One Sample Z Test in Excel?
Yes. Excel can calculate the test using COUNT, AVERAGE, STDEV.S, SQRT and NORM.S.DIST formulas.
Is a One Sample Z Test the same as a One Proportion Z Test?
No. A One Sample Z Test compares one mean with a hypothesized mean. A One Proportion Z Test compares one observed proportion with a hypothesized proportion.
When should I use a t test instead of a z test?
Use a one-sample t test when the population standard deviation is unknown and must be estimated from the sample, especially in smaller samples.
Google AdSense bottom placement reserved here


